
Usando gli hypernetwork, i ricercatori possono ora mettere a punto preventivamente le reti neurali artificiali, risparmiando parte del tempo e delle spese di formazione.
L'intelligenza artificiale è in gran parte un gioco di numeri. Quando le reti neurali profonde, una forma di IA che impara a discernere i modelli nei dati, hanno iniziato a superare gli algoritmi tradizionali 10 anni fa, è stato perché finalmente avevamo abbastanza dati e potenza di elaborazione per farne pieno uso.
Le reti neurali di oggi sono ancora più affamate di dati e potenza. L'addestramento richiede un'attenta regolazione dei valori di milioni o addirittura miliardi di parametri che caratterizzano queste reti, che rappresentano la forza delle connessioni tra i neuroni artificiali. L'obiettivo è quello di trovare valori quasi ideali per loro, un processo noto come ottimizzazione, ma allenare le reti per raggiungere questo punto non è facile. "L'addestramento potrebbe richiedere giorni, settimane o addirittura mesi", ha detto Petar Veličković, uno scienziato ricercatore presso DeepMind a Londra.
Questo potrebbe presto cambiare. Boris Knyazev dell'Università di Guelph in Ontario e i suoi colleghi hanno progettato e addestrato un "hypernetwork" - una sorta di overlord di altre reti neurali - che potrebbe accelerare il processo di formazione. Data una nuova rete neurale profonda non addestrata progettata per qualche compito, l'hypernetwork predice i parametri per la nuova rete in frazioni di secondo, e in teoria potrebbe rendere inutile l'addestramento. Poiché l'hypernetwork impara i modelli estremamente complessi nei disegni delle reti neurali profonde, il lavoro potrebbe anche avere implicazioni teoriche più profonde.
Per ora, l'hypernetwork si comporta sorprendentemente bene in alcune impostazioni, ma c'è ancora spazio per crescere - che è solo naturale data la grandezza del problema. Se riusciranno a risolverlo, "questo avrà un forte impatto su tutta la linea per l'apprendimento automatico", ha detto Veličković.
Diventare iper
Attualmente, i migliori metodi per addestrare e ottimizzare le reti neurali profonde sono variazioni di una tecnica chiamata discesa del gradiente stocastico (SGD). L'addestramento consiste nel minimizzare gli errori che la rete fa in un dato compito, come il riconoscimento delle immagini. Un algoritmo SGD sforna un sacco di dati etichettati per regolare i parametri della rete e ridurre gli errori, o perdite. La discesa del gradiente è il processo iterativo di scendere da valori elevati della funzione di perdita a qualche valore minimo, che rappresenta valori dei parametri abbastanza buoni (o a volte anche i migliori possibili).
Ma questa tecnica funziona solo quando si ha una rete da ottimizzare. Per costruire la rete neurale iniziale, tipicamente composta da più strati di neuroni artificiali che portano da un input a un output, gli ingegneri devono affidarsi a intuizioni e regole empiriche. Queste architetture possono variare in termini di numero di strati di neuroni, il numero di neuroni per strato, e così via.
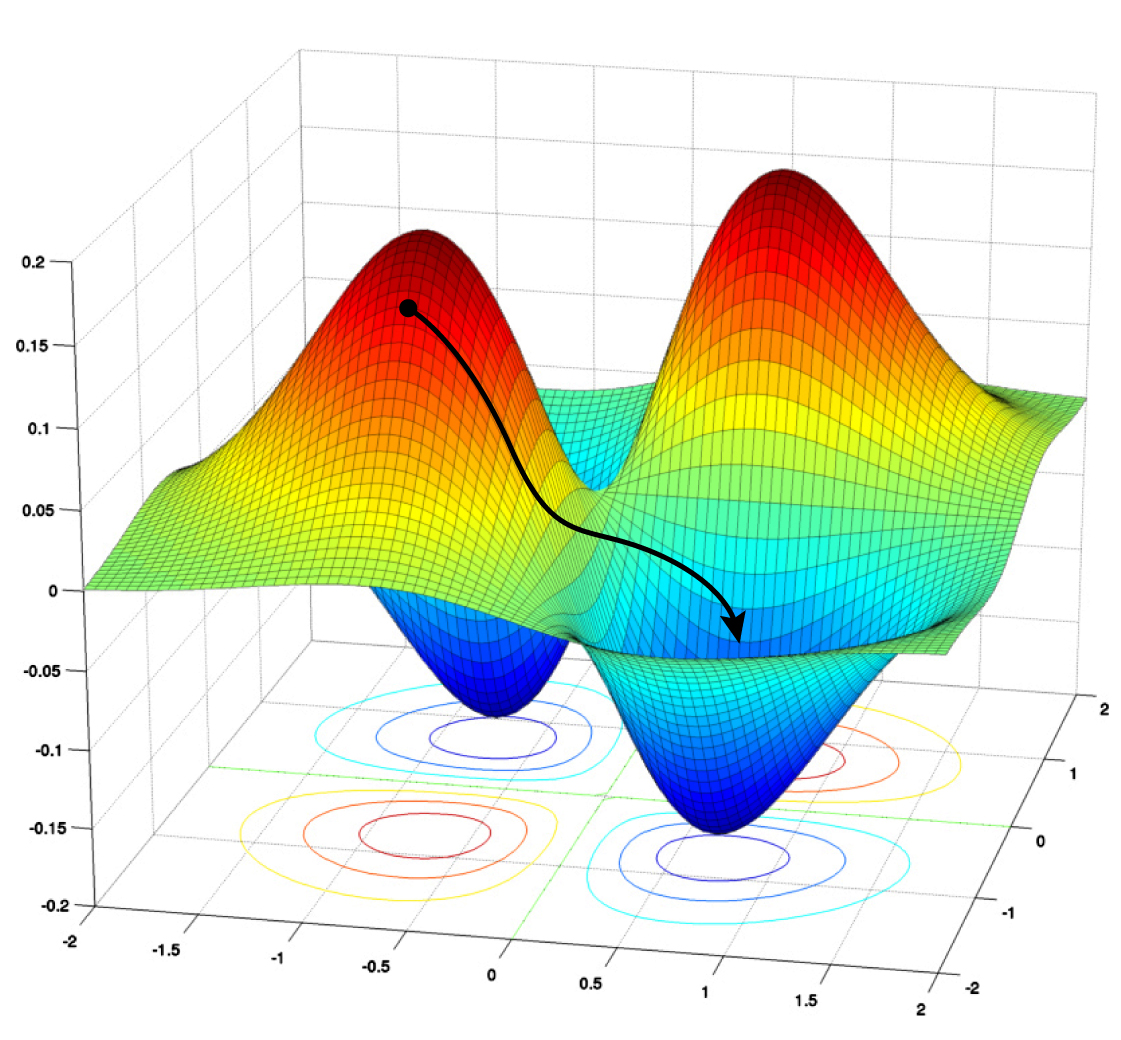 |
| La discesa del gradiente porta una rete lungo il suo "paesaggio di perdita", dove i valori più alti rappresentano errori maggiori, o perdita. L'algoritmo cerca di trovare il valore minimo globale per minimizzare la perdita. |
Si può, in teoria, iniziare con molte architetture, poi ottimizzare ciascuna di esse e scegliere la migliore. "Ma l'addestramento [richiede] una quantità di tempo non banale", ha detto Mengye Ren, ora ricercatore in visita a Google Brain. Sarebbe impossibile addestrare e testare ogni architettura di rete candidata. "[Non] scala molto bene, soprattutto se si considerano milioni di disegni possibili".
Così nel 2018, Ren, insieme al suo ex collega dell'Università di Toronto Chris Zhang e al loro consulente Raquel Urtasun, ha provato un approccio diverso. Hanno progettato quello che hanno chiamato un hypernetwork grafico (GHN) per trovare la migliore architettura di rete neurale profonda per risolvere qualche compito, dato un insieme di architetture candidate.
Il nome delinea il loro approccio. "Grafo" si riferisce all'idea che l'architettura di una rete neurale profonda può essere pensata come un grafico matematico - un insieme di punti, o nodi, collegati da linee, o bordi. Qui i nodi rappresentano unità computazionali (di solito, un intero strato di una rete neurale), e i bordi rappresentano il modo in cui queste unità sono interconnesse.
Ecco come funziona. Un hypernetwork grafico inizia con una qualsiasi architettura che deve essere ottimizzata (chiamiamolo il candidato). Poi fa del suo meglio per prevedere i parametri ideali per il candidato. Il team quindi imposta i parametri di una rete neurale reale sui valori previsti e la testa su un dato compito. Il team di Ren ha dimostrato che questo metodo potrebbe essere usato per classificare le architetture candidate e selezionare il migliore.
Quando Knyazev e i suoi colleghi si sono imbattuti nell'idea dell'hypernetwork a grafo, si sono resi conto che potevano costruirci sopra. Nel loro nuovo documento, il team mostra come utilizzare i GHN non solo per trovare la migliore architettura da un certo insieme di campioni, ma anche per prevedere i parametri per la migliore rete in modo che si comporti bene in senso assoluto. E nelle situazioni in cui la migliore non è abbastanza buona, la rete può essere addestrata ulteriormente usando la discesa del gradiente.
"È un documento molto solido. [Contiene molta più sperimentazione di quella che abbiamo fatto noi", ha detto Ren del nuovo lavoro. "Lavorano molto duramente per spingere in alto le prestazioni assolute, il che è bello da vedere".
Addestrare il formatore
Knyazev e il suo team chiamano il loro hypernetwork GHN-2, e migliora due aspetti importanti dell'hypernetwork grafico costruito da Ren e colleghi.
In primo luogo, si sono basati sulla tecnica di Ren di rappresentare l'architettura di una rete neurale come un grafico. Ogni nodo del grafico codifica le informazioni su un sottoinsieme di neuroni che fanno un certo tipo specifico di calcolo. I bordi del grafico descrivono come le informazioni fluiscono da nodo a nodo, dall'input all'output.
La seconda idea a cui hanno attinto è il metodo di addestramento dell'ipernetwork per fare previsioni per nuove architetture candidate. Questo richiede altre due reti neurali. La prima permette di effettuare calcoli sul grafo candidato originale, con il risultato di aggiornare le informazioni associate ad ogni nodo, e la seconda prende i nodi aggiornati come input e predice i parametri per le unità computazionali corrispondenti della rete neurale candidata. Queste due reti hanno anche i loro parametri, che devono essere ottimizzati prima che l'ipernetwork possa predire correttamente i valori dei parametri.

Per fare questo, avete bisogno di dati di allenamento - in questo caso, un campione casuale di possibili architetture di reti neurali artificiali (ANN). Per ogni architettura nel campione, si inizia con un grafico, e poi si usa l'hypernetwork del grafico per prevedere i parametri e inizializzare la RNA candidata con i parametri predetti. La RNA poi esegue un compito specifico, come il riconoscimento di un'immagine. Si calcola la perdita fatta dalla RNA e poi - invece di aggiornare i parametri della RNA per fare una previsione migliore - si aggiornano i parametri dell'hypernetwork che ha fatto la previsione in primo luogo. Questo permette all'ipernetwork di fare meglio la volta successiva. Ora, iterate su ogni immagine in qualche set di dati di addestramento etichettati e su ogni RNA nel campione casuale di architetture, riducendo la perdita ad ogni passo, finché non può fare meglio. Ad un certo punto, si finisce con un hypernetwork addestrato.
Il team di Knyazev ha preso queste idee e ha scritto il proprio software da zero, poiché il team di Ren non ha reso pubblico il proprio codice sorgente. Poi Knyazev e colleghi lo hanno migliorato. Per cominciare, hanno identificato 15 tipi di nodi che possono essere mescolati e abbinati per costruire quasi ogni moderna rete neurale profonda. Hanno anche fatto diversi progressi per migliorare l'accuratezza della previsione.
Più significativamente, per garantire che GHN-2 impari a predire i parametri per una vasta gamma di architetture di reti neurali di destinazione, Knyazev e colleghi hanno creato un unico set di dati di 1 milione di architetture possibili. "Per addestrare il nostro modello, abbiamo creato architetture casuali [che sono] il più diverse possibile", ha detto Knyazev.
Come risultato, l'abilità predittiva di GHN-2 ha maggiori probabilità di generalizzare bene alle architetture di destinazione non viste. "Possono, per esempio, tenere conto di tutte le architetture tipiche dello stato dell'arte che le persone usano", ha detto Thomas Kipf, uno scienziato ricercatore presso il Brain Team di Google Research ad Amsterdam. "Questo è un grande contributo".
Risultati impressionanti
Il vero test, naturalmente, è stato mettere GHN-2 al lavoro. Una volta che Knyazev e il suo team lo hanno addestrato a predire i parametri per un dato compito, come classificare le immagini in un particolare set di dati, hanno testato la sua capacità di predire i parametri per qualsiasi architettura candidata casuale. Questo nuovo candidato potrebbe avere proprietà simili al milione di architetture nel set di dati di allenamento, o potrebbe essere diverso - una sorta di outlier. Nel primo caso, si dice che l'architettura target è in distribuzione; nel secondo, è fuori distribuzione. Le reti neurali profonde spesso falliscono quando fanno previsioni per quest'ultimo caso, quindi testare GHN-2 su tali dati era importante.
Armati di una GHN-2 completamente addestrata, il team ha predetto i parametri per 500 architetture di rete a bersaglio casuale precedentemente inedite. Poi queste 500 reti, con i loro parametri impostati sui valori previsti, sono state messe a confronto con le stesse reti addestrate utilizzando la discesa del gradiente stocastico. Il nuovo hypernetwork ha spesso tenuto testa a migliaia di iterazioni di SGD, e a volte ha fatto anche meglio, anche se alcuni risultati sono stati più contrastanti.
Per un set di dati di immagini noto come CIFAR-10, l'accuratezza media di GHN-2 su architetture in-distribuzione è stata del 66,9%, che si è avvicinata all'accuratezza media del 69,2% raggiunta dalle reti addestrate utilizzando 2.500 iterazioni di SGD. Per le architetture fuori distribuzione, GHN-2 ha fatto sorprendentemente bene, raggiungendo circa il 60% di accuratezza. In particolare, ha raggiunto un rispettabile 58,6% di precisione per una specifica architettura di rete neurale profonda ben nota chiamata ResNet-50. "La generalizzazione a ResNet-50 è sorprendentemente buona, dato che ResNet-50 è circa 20 volte più grande della nostra architettura media di formazione", ha detto Knyazev, parlando a NeurIPS 2021, l'incontro di punta del campo.
GHN-2 non è andato altrettanto bene con ImageNet, un set di dati notevolmente più grande: In media, era solo circa il 27,2% di precisione. Eppure, questo si confronta favorevolmente con l'accuratezza media del 25,6% per le stesse reti addestrate utilizzando 5.000 passi di SGD. (Naturalmente, se si continua a usare SGD, si può alla fine - a un costo considerevole - finire con il 95% di accuratezza). La cosa più cruciale è che GHN-2 ha fatto le sue previsioni di ImageNet in meno di un secondo, mentre l'utilizzo di SGD per ottenere le stesse prestazioni dei parametri predetti ha richiesto, in media, 10.000 volte più tempo sulla loro unità di elaborazione grafica (l'attuale cavallo di battaglia dell'addestramento delle reti neurali profonde).
"I risultati sono decisamente super impressionanti", ha detto Veličković. "Fondamentalmente abbattono i costi energetici in modo significativo".
E quando GHN-2 trova la migliore rete neurale per un compito da un campionamento di architetture, e quella migliore opzione non è abbastanza buona, almeno il vincitore è ora parzialmente addestrato e può essere ottimizzato ulteriormente. Invece di scatenare SGD su una rete inizializzata con valori casuali per i suoi parametri, si possono usare le previsioni di GHN-2 come punto di partenza. "Essenzialmente imitiamo il pre-addestramento", ha detto Knyazev.
Oltre GHN-2
Nonostante questi successi, Knyazev pensa che la comunità di apprendimento automatico in un primo momento resisterà all'uso delle iperreti a grafo. Lo paragona alla resistenza affrontata dalle reti neurali profonde prima del 2012. Allora, i professionisti dell'apprendimento automatico preferivano algoritmi progettati a mano piuttosto che le misteriose reti profonde. Ma questo è cambiato quando le massicce reti profonde addestrate su enormi quantità di dati hanno iniziato a superare gli algoritmi tradizionali. "Questo può andare nello stesso modo".
Nel frattempo, Knyazev vede molte opportunità di miglioramento. Per esempio, GHN-2 può essere addestrato solo per prevedere i parametri per risolvere un dato compito, come classificare le immagini CIFAR-10 o ImageNet, ma non allo stesso tempo. In futuro, immagina di addestrare gli hypernetwork grafici su una maggiore diversità di architetture e su diversi tipi di compiti (riconoscimento delle immagini, riconoscimento vocale ed elaborazione del linguaggio naturale, per esempio). Poi la predizione può essere condizionata sia dall'architettura di destinazione che dal compito specifico a portata di mano.
E se queste hypernetwork decollano, la progettazione e lo sviluppo di nuove reti neurali profonde non saranno più limitate alle aziende con tasche profonde e accesso a grandi dati. Chiunque potrebbe entrare in azione. Knyazev è ben consapevole di questo potenziale per "democratizzare l'apprendimento profondo", definendolo una visione a lungo termine.
Tuttavia, Veličković evidenzia un problema potenzialmente grande se le iperreti come GHN-2 diventeranno mai il metodo standard per ottimizzare le reti neurali. Con le iperreti a grafo, ha detto, "si ha una rete neurale - essenzialmente una scatola nera - che predice i parametri di un'altra rete neurale. Quindi, quando commette un errore, non si ha modo di spiegarlo".
Naturalmente, questo è già in gran parte il caso delle reti neurali. "Non la chiamerei una debolezza", ha detto Veličković. "Lo chiamerei un segnale d'allarme".
Kipf, tuttavia, vede un rivestimento d'argento. "Qualcosa [altro] mi ha eccitato di più". GHN-2 mette in mostra la capacità delle reti neurali a grafo di trovare modelli in dati complicati.
Normalmente, le reti neurali profonde trovano modelli in immagini o testo o segnali audio, che sono tipi di informazioni abbastanza strutturate. GHN-2 trova modelli nei grafici di architetture di reti neurali completamente casuali. "Sono dati molto complicati".
Eppure, GHN-2 può generalizzare - il che significa che può fare previsioni ragionevoli dei parametri per architetture di rete inedite e persino fuori distribuzione. "Questo lavoro ci mostra che molti modelli sono in qualche modo simili in diverse architetture, e un modello può imparare come trasferire la conoscenza da un'architettura ad un'altra", ha detto Kipf. "Questo è qualcosa che potrebbe ispirare qualche nuova teoria per le reti neurali".
Se questo è il caso, potrebbe portare ad una nuova e maggiore comprensione di queste scatole nere.
Pubblicato su quantamagazine
Posta un commento
Condividi la tua opinione nel rispetto degli altri. Link e materiale non pertinente sarà eliminato.